PostgreSQL
Sources:
- Most of the examples are from https://pgexercises.com/
- Most of the notes are from https://www.postgresql.org/docs/12
Notes

Aggregates
Aggregates are also very useful in combination with GROUP BY clauses. For example, we can get the maximum low temperature observed in each city with:
SELECT city, max(temp_lo)
FROM weather
GROUP BY city;
city | max
---------------+-----
Hayward | 37
San Francisco | 46
(2 rows)
which gives us one output row per city. Each aggregate result is computed over the table rows matching that city. We can filter these grouped rows using HAVING:
SELECT city, max(temp_lo)
FROM weather
GROUP BY city
HAVING max(temp_lo) < 40;
city | max
---------+-----
Hayward | 37
(1 row)
which gives us the same results for only the cities that have all temp_lo values below 40. Finally, if we only care about cities whose names begin with “S”, we might do:
SELECT city, max(temp_lo)
FROM weather
WHERE city LIKE 'S%' -- (1)
GROUP BY city
HAVING max(temp_lo) < 40;
It is important to understand the interaction between aggregates and SQL’s WHERE and HAVING clauses. The fundamental difference between WHERE and HAVING is this: WHERE selects input rows before groups and aggregates are computed (thus, it controls which rows go into the aggregate computation), whereas HAVING selects group rows after groups and aggregates are computed. Thus, the WHERE clause must not contain aggregate functions; it makes no sense to try to use an aggregate to determine which rows will be inputs to the aggregates. On the other hand, the HAVING clause always contains aggregate functions. (Strictly speaking, you are allowed to write a HAVING clause that doesn’t use aggregates, but it’s seldom useful. The same condition could be used more efficiently at the WHERE stage.)
Aggregate Function List
array_agg(expr)avg(expr)bit_and(expr)bit_or(expr)bool_and(expr)|every(expr)bool_or(expr)count(*)max(expr)min(expr)sum(expr)- Aggregate functions for statistics
- Full aggregate function list
Window Functions
A window function performs a calculation across a set of table rows that are somehow related to the current row.
This is comparable to the type of calculation that can be done with an aggregate function. However, window functions do not cause rows to become grouped into a single output row like non-window aggregate calls would. Instead, the rows retain their separate identities. Behind the scenes, the window function is able to access more than just the current row of the query result.
Here is an example that shows how to compare each employee’s salary with the average salary in his or her department:
SELECT depname, empno, salary, avg(salary) OVER (PARTITION BY depname) FROM empsalary;
depname | empno | salary | avg
-----------+-------+--------+-----------------------
develop | 11 | 5200 | 5020.0000000000000000
develop | 7 | 4200 | 5020.0000000000000000
develop | 9 | 4500 | 5020.0000000000000000
develop | 8 | 6000 | 5020.0000000000000000
develop | 10 | 5200 | 5020.0000000000000000
personnel | 5 | 3500 | 3700.0000000000000000
personnel | 2 | 3900 | 3700.0000000000000000
sales | 3 | 4800 | 4866.6666666666666667
sales | 1 | 5000 | 4866.6666666666666667
sales | 4 | 4800 | 4866.6666666666666667
(10 rows)
The first three output columns come directly from the table empsalary, and there is one output row for each row in the table. The fourth column represents an average taken across all the table rows that have the same depname value as the current row. (This actually is the same function as the non-window avg aggregate, but the OVER clause causes it to be treated as a window function and computed across the window frame.)
A window function call always contains an OVER clause directly following the window function’s name and argument(s). This is what syntactically distinguishes it from a normal function or non-window aggregate. The OVER clause determines exactly how the rows of the query are split up for processing by the window function. The PARTITION BY clause within OVER divides the rows into groups, or partitions, that share the same values of the PARTITION BY expression(s). For each row, the window function is computed across the rows that fall into the same partition as the current row.
You can also control the order in which rows are processed by window functions using ORDER BY within OVER. (The window ORDER BY does not even have to match the order in which the rows are output.) Here is an example:
SELECT depname, empno, salary,
rank() OVER (PARTITION BY depname ORDER BY salary DESC)
FROM empsalary;
depname | empno | salary | rank
-----------+-------+--------+------
develop | 8 | 6000 | 1
develop | 10 | 5200 | 2
develop | 11 | 5200 | 2
develop | 9 | 4500 | 4
develop | 7 | 4200 | 5
personnel | 2 | 3900 | 1
personnel | 5 | 3500 | 2
sales | 1 | 5000 | 1
sales | 4 | 4800 | 2
sales | 3 | 4800 | 2
(10 rows)
As shown here, the rank function produces a numerical rank for each distinct ORDER BY value in the current row’s partition, using the order defined by the ORDER BY clause. rank needs no explicit parameter, because its behavior is entirely determined by the OVER clause.
The rows considered by a window function are those of the “virtual table” produced by the query’s FROM clause as filtered by its WHERE, GROUP BY, and HAVING clauses if any. For example, a row removed because it does not meet the WHERE condition is not seen by any window function. A query can contain multiple window functions that slice up the data in different ways using different OVER clauses, but they all act on the same collection of rows defined by this virtual table.
We already saw that ORDER BY can be omitted if the ordering of rows is not important. It is also possible to omit PARTITION BY, in which case there is a single partition containing all rows.
There is another important concept associated with window functions: for each row, there is a set of rows within its partition called its window frame. Some window functions act only on the rows of the window frame, rather than of the whole partition. By default, if ORDER BY is supplied then the frame consists of all rows from the start of the partition up through the current row, plus any following rows that are equal to the current row according to the ORDER BY clause. When ORDER BY is omitted the default frame consists of all rows in the partition. [4] Here is an example using sum:
SELECT salary, sum(salary) OVER () FROM empsalary;
salary | sum
--------+-------
5200 | 47100
5000 | 47100
3500 | 47100
4800 | 47100
3900 | 47100
4200 | 47100
4500 | 47100
4800 | 47100
6000 | 47100
5200 | 47100
(10 rows)
Above, since there is no ORDER BY in the OVER clause, the window frame is the same as the partition, which for lack of PARTITION BY is the whole table; in other words each sum is taken over the whole table and so we get the same result for each output row. But if we add an ORDER BY clause, we get very different results:
SELECT salary, sum(salary) OVER (ORDER BY salary) FROM empsalary;
salary | sum
--------+-------
3500 | 3500
3900 | 7400
4200 | 11600
4500 | 16100
4800 | 25700
4800 | 25700
5000 | 30700
5200 | 41100
5200 | 41100
6000 | 47100
(10 rows)
Here the sum is taken from the first (lowest) salary up through the current one, including any duplicates of the current one (notice the results for the duplicated salaries).
Window functions are permitted only in the SELECT list and the ORDER BY clause of the query. They are forbidden elsewhere, such as in GROUP BY, HAVING and WHERE clauses. This is because they logically execute after the processing of those clauses. Also, window functions execute after non-window aggregate functions. This means it is valid to include an aggregate function call in the arguments of a window function, but not vice versa.
If there is a need to filter or group rows after the window calculations are performed, you can use a sub-select. For example:
SELECT depname, empno, salary, enroll_date
FROM
(SELECT depname, empno, salary, enroll_date,
rank() OVER (PARTITION BY depname ORDER BY salary DESC, empno) AS pos
FROM empsalary
) AS ss
WHERE pos < 3;
The above query only shows the rows from the inner query having rank less than 3.
When a query involves multiple window functions, it is possible to write out each one with a separate OVER clause, but this is duplicative and error-prone if the same windowing behavior is wanted for several functions. Instead, each windowing behavior can be named in a WINDOW clause and then referenced in OVER. For example:
SELECT sum(salary) OVER w, avg(salary) OVER w
FROM empsalary
WINDOW w AS (PARTITION BY depname ORDER BY salary DESC);
Window Function List
Window functions provide the ability to perform calculations across sets of rows that are related to the current query row.
In addition to these functions, any built-in or user-defined general-purpose or statistical aggregate (i.e., not ordered-set or hypothetical-set aggregates) can be used as a window function. Aggregate functions act as window functions only when an OVER clause follows the call; otherwise they act as non-window aggregates and return a single row for the entire set.
row_number()rank()dense_rank()percent_rant()ntile(num_buckets integer)- Full window function list
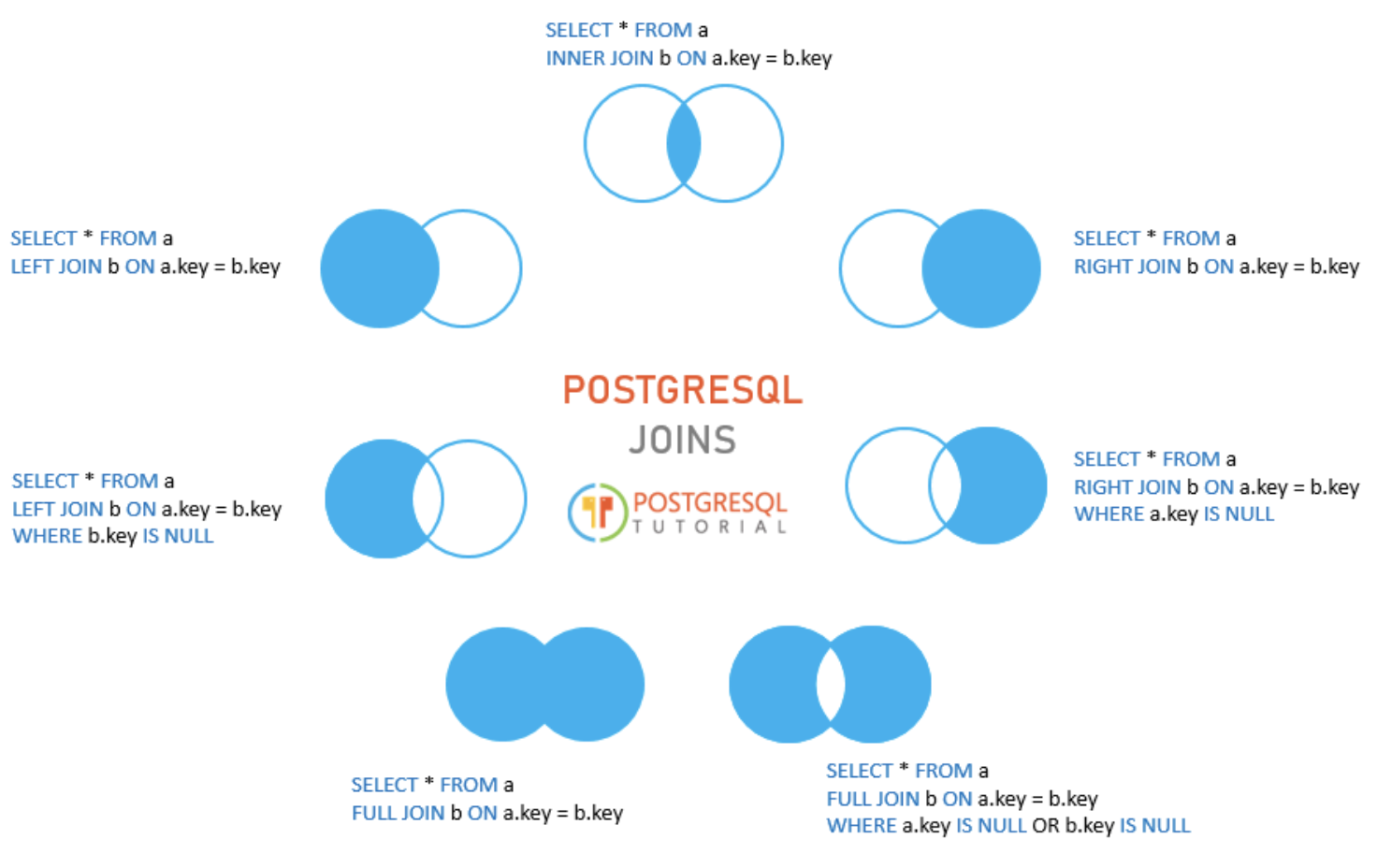
Joins
Updates
You can update existing rows using the UPDATE command. Suppose you discover the temperature readings are all off by 2 degrees after November 28. You can correct the data as follows:
UPDATE weather
SET temp_hi = temp_hi - 2, temp_lo = temp_lo - 2
WHERE date > '1994-11-28';
Populating
You can list the columns in a different order if you wish or even omit some columns, e.g., if the precipitation is unknown:
INSERT INTO weather (date, city, temp_hi, temp_lo)
VALUES ('1994-11-29', 'Hayward', 54, 37);
Views
You can create a view over the query, which gives a name to the query that you can refer to like an ordinary table:
CREATE VIEW myview AS
SELECT city, temp_lo, temp_hi, prcp, date, location
FROM weather, cities
WHERE city = name;
SELECT * FROM myview;
Making liberal use of views is a key aspect of good SQL database design. Views allow you to encapsulate the details of the structure of your tables, which might change as your application evolves, behind consistent interfaces.
Views can be used in almost any place a real table can be used. Building views upon other views is not uncommon.
WITH Queries
WITH provides a way to write auxiliary statements for use in a larger query. These statements, which are often referred to as Common Table Expressions or CTEs, can be thought of as defining temporary tables that exist just for one query. Each auxiliary statement in a WITH clause can be a SELECT, INSERT, UPDATE, or DELETE; and the WITH clause itself is attached to a primary statement that can also be a SELECT, INSERT, UPDATE, or DELETE.
The basic value of SELECT in WITH is to break down complicated queries into simpler parts. An example is:
WITH regional_sales AS (
SELECT region, SUM(amount) AS total_sales
FROM orders
GROUP BY region
), top_regions AS (
SELECT region
FROM regional_sales
WHERE total_sales > (SELECT SUM(total_sales)/10 FROM regional_sales)
)
SELECT region,
product,
SUM(quantity) AS product_units,
SUM(amount) AS product_sales
FROM orders
WHERE region IN (SELECT region FROM top_regions)
GROUP BY region, product;
which displays per-product sales totals in only the top sales regions. The WITH clause defines two auxiliary statements named regional_sales and top_regions, where the output of regional_sales is used in top_regions and the output of top_regions is used in the primary SELECT query. This example could have been written without WITH, but we’d have needed two levels of nested sub-SELECTs. It’s a bit easier to follow this way.
The optional RECURSIVE modifier changes WITH from a mere syntactic convenience into a feature that accomplishes things not otherwise possible in standard SQL. Using RECURSIVE, a WITH query can refer to its own output. A very simple example is this query to sum the integers from 1 through 100:
WITH RECURSIVE t(n) AS (
VALUES (1)
UNION ALL
SELECT n+1 FROM t WHERE n < 100
)
SELECT sum(n) FROM t;
The general form of a recursive WITH query is always a non-recursive term, then UNION (or UNION ALL), then a recursive term, where only the recursive term can contain a reference to the query’s own output.
Foreign Keys
Consider the following problem: You want to make sure that no one can insert rows in the weather table that do not have a matching entry in the cities table. This is called maintaining the referential integrity of your data. In simplistic database systems this would be implemented (if at all) by first looking at the cities table to check if a matching record exists, and then inserting or rejecting the new weather records. This approach has a number of problems and is very inconvenient, so PostgreSQL can do this for you.
The new declaration of the tables would look like this:
CREATE TABLE cities (
city varchar(80) primary key,
location point
);
CREATE TABLE weather (
city varchar(80) references cities(city),
temp_lo int,
temp_hi int,
prcp real,
date date
);
Transactions
Transactions are a fundamental concept of all database systems. The essential point of a transaction is that it bundles multiple steps into a single, all-or-nothing operation. The intermediate states between the steps are not visible to other concurrent transactions, and if some failure occurs that prevents the transaction from completing, then none of the steps affect the database at all.
In PostgreSQL, a transaction is set up by surrounding the SQL commands of the transaction with BEGIN and COMMIT commands. So our banking transaction would actually look like:
BEGIN;
UPDATE accounts SET balance = balance - 100.00
WHERE name = 'Alice';
-- etc etc
COMMIT;
If, partway through the transaction, we decide we do not want to commit (perhaps we just noticed that Alice’s balance went negative), we can issue the command ROLLBACK instead of COMMIT, and all our updates so far will be canceled.
Indexes
Basics
Suppose we have a table similar to this:
CREATE TABLE test1 (
id integer,
content varchar
);
and the application issues many queries of the form:
SELECT content FROM test1 WHERE id = constant; With no advance preparation, the system would have to scan the entire test1 table, row by row, to find all matching entries. If there are many rows in test1 and only a few rows (perhaps zero or one) that would be returned by such a query, this is clearly an inefficient method. But if the system has been instructed to maintain an index on the id column, it can use a more efficient method for locating matching rows. For instance, it might only have to walk a few levels deep into a search tree.
A similar approach is used in most non-fiction books: terms and concepts that are frequently looked up by readers are collected in an alphabetic index at the end of the book. The interested reader can scan the index relatively quickly and flip to the appropriate page(s), rather than having to read the entire book to find the material of interest. Just as it is the task of the author to anticipate the items that readers are likely to look up, it is the task of the database programmer to foresee which indexes will be useful.
The following command can be used to create an index on the id column, as discussed:
CREATE INDEX test1_id_index ON test1 (id);
The name test1_id_index can be chosen freely, but you should pick something that enables you to remember later what the index was for.
To remove an index, use the DROP INDEX command. Indexes can be added to and removed from tables at any time.
Once an index is created, no further intervention is required: the system will update the index when the table is modified, and it will use the index in queries when it thinks doing so would be more efficient than a sequential table scan. But you might have to run the ANALYZE command regularly to update statistics to allow the query planner to make educated decisions
Indexes can also benefit UPDATE and DELETE commands with search conditions. Indexes can moreover be used in join searches. Thus, an index defined on a column that is part of a join condition can also significantly speed up queries with joins.
Creating an index on a large table can take a long time. By default, PostgreSQL allows reads (SELECT statements) to occur on the table in parallel with index creation, but writes (INSERT, UPDATE, DELETE) are blocked until the index build is finished. In production environments this is often unacceptable. It is possible to allow writes to occur in parallel with index creation, but there are several caveats to be aware of — for more information see Building Indexes Concurrently.
After an index is created, the system has to keep it synchronized with the table. This adds overhead to data manipulation operations. Therefore indexes that are seldom or never used in queries should be removed.
Multicolumn Indexes
An index can be defined on more than one column of a table. For example, if you have a table of this form:
CREATE TABLE test2 (
major int,
minor int,
name varchar
);
(say, you keep your /dev directory in a database…) and you frequently issue queries like:
SELECT name FROM test2 WHERE major = constant AND minor = constant; then it might be appropriate to define an index on the columns major and minor together, e.g.:
CREATE INDEX test2_mm_idx ON test2 (major, minor);
Examples
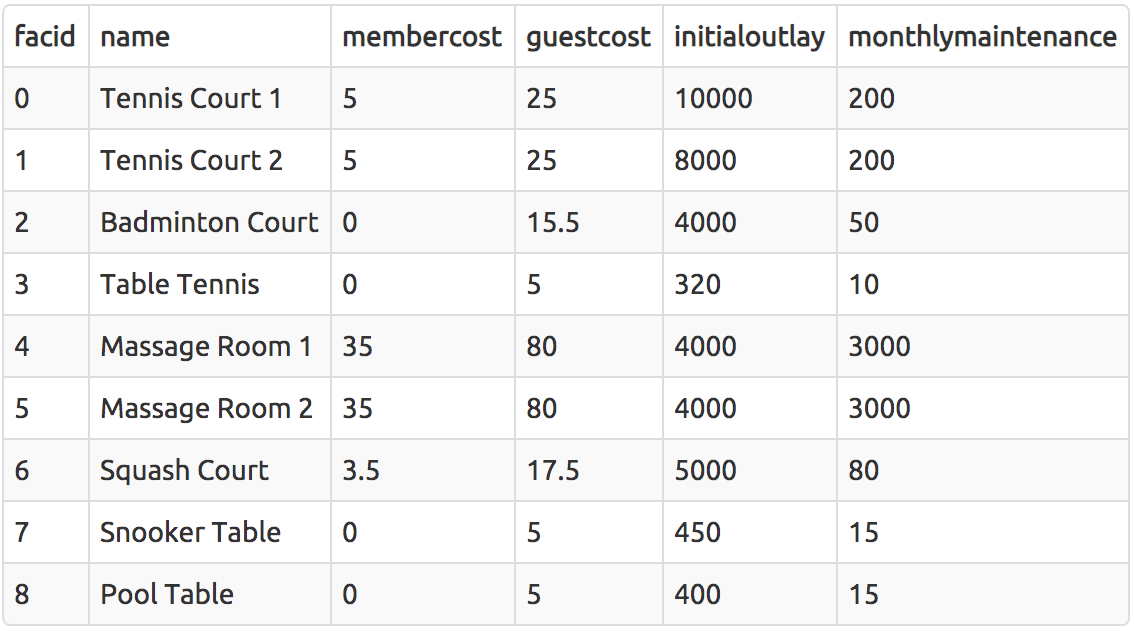
Retrieve everything from a table
SELECT * FROM cd.facilities;
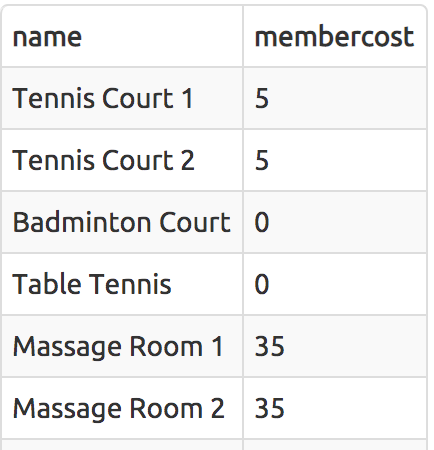
Retrieve specific columns from a table
SELECT name, membercost FROM cd.facilities;
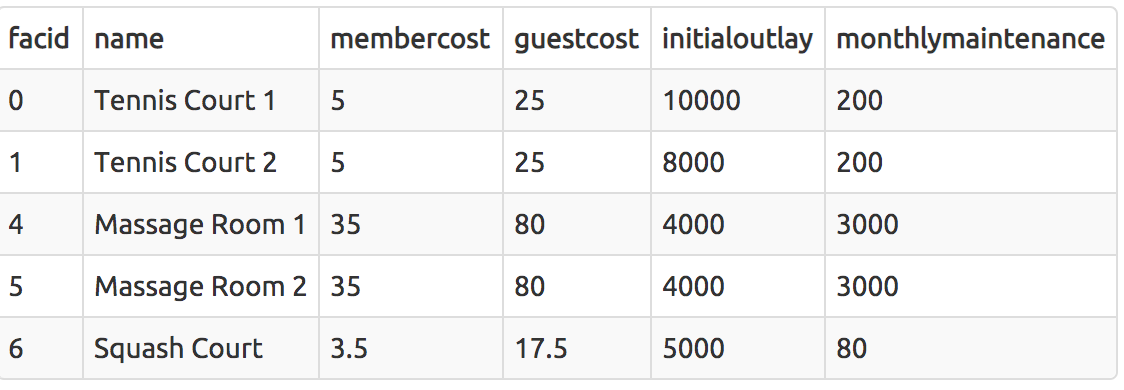
Control which rows are retrieved
SELECT * FROM cd.facilities WHERE membercost > 0;
Control which rows are retrieved - part 2
SELECT
facid, name, membercost, monthlymaintenance
FROM
cd.facilities
WHERE
membercost > 0
AND
membercost < (1.0/50.0) * monthlymaintenance
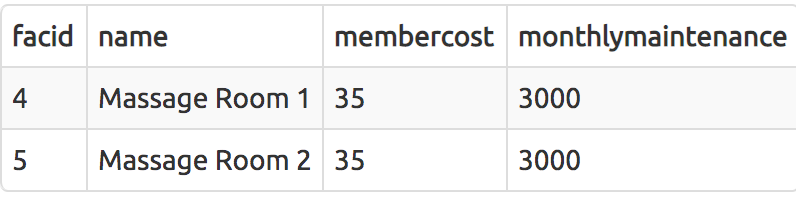
Basic string searches
SELECT * from cd.facilities WHERE name LIKE '%Tennis%';
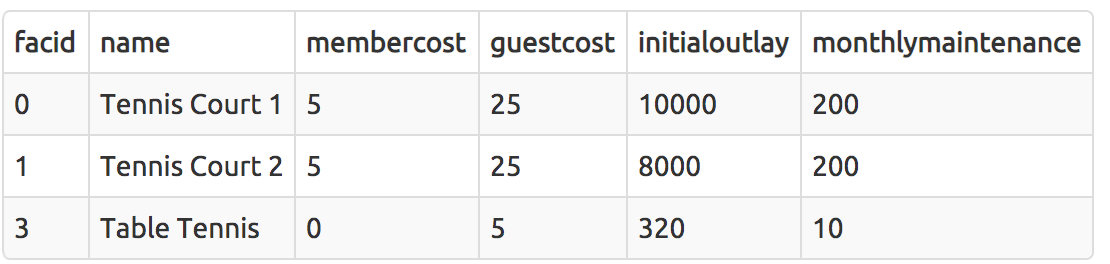
Matching against multiple possible values
SELECT * FROM cd.facilities WHERE facid in (1,5);

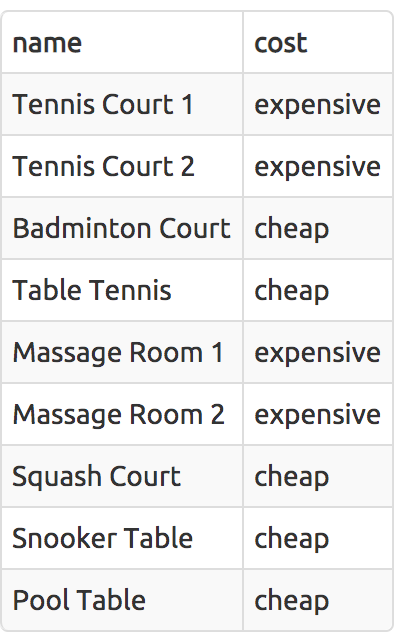
Classify results into buckets
SELECT
name,
CASE
WHEN
monthlymaintenance > 100 THEN 'expensive'
ELSE 'cheap'
END AS cost
FROM cd.facilities;
Working with dates
SELECT memid, surname, firstname, joindate FROM cd.members WHERE joindate >= '2012-09-01'
Removing duplicates and ordering results
SELECT DISTINCT surname FROM cd.members ORDER BY surname LIMIT 10;
Combining results from multiple queries
SELECT surname FROM cd.members UNION SELECT NAME FROM cd.facilities
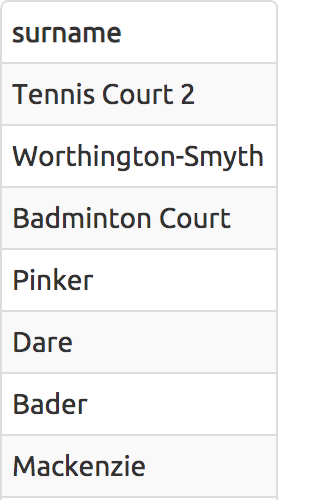
Simple aggregation
SELECT MAX(joindate) AS latest FROM cd.members
More aggregation
SELECT firstname, surname, joindate FROM cd.members ORDER BY joindate DESC LIMIT 1
Retrieve the start times of members’ bookings
SELECT
bks.starttime
FROM
cd.bookings bks
INNER JOIN
cd.members mbs
ON
mbs.memid = bks.memid
WHERE
mbs.firstname = 'David'
AND
mbs.surname = 'Farrell';
Retrieve the start times of members’ bookings (alt syntax)
SELECT bks.starttime FROM cd.bookings bks, cd.members mems WHERE mems.firstname='David' AND mems.surname='Farrell' AND mems.memid = bks.memid;
Work out the start times of bookings for tennis courts
SELECT
bks.starttime,
fls.name
FROM
cd.bookings bks
INNER JOIN cd.facilities fls ON bks.facid = fls.facid
WHERE
fls.name LIKE '%Tennis%Court%'
AND bks.starttime >= '2012-09-21'
AND bks.starttime < '2012-09-22'
ORDER BY bks.starttime ASC
Produce a list of all members who have recommended another member
SELECT DISTINCT
mbs1.firstname,
mbs1.surname
FROM
cd.members mbs1
INNER JOIN cd.members mbs2 ON mbs2.recommendedby = mbs1.memid
ORDER BY
mbs1.surname,
mbs1.firstname
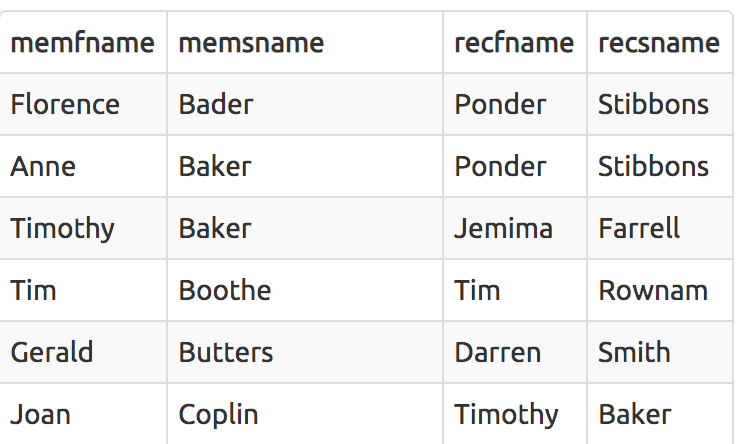
Produce a list of all members, along with their recommender
SELECT
mems.firstname AS memfname,
mems.surname AS memsname,
recs.firstname AS recfname,
recs.surname AS recsname
FROM
cd.members mems
LEFT OUTER JOIN cd.members recs ON recs.memid = mems.recommendedby
ORDER BY
memsname,
memfname
3-way join: Produce a list of all members who have used a tennis court
SELECT DISTINCT
mems.firstname || ' ' || mems.surname AS member,
facs.name AS facility
FROM
cd.members mems
INNER JOIN cd.bookings bks ON mems.memid = bks.memid
INNER JOIN cd.facilities facs ON bks.facid = facs.facid
WHERE
facs.name LIKE '%Tennis Court%'
ORDER BY
member ASC,
facility DESC
Produce a list of costly bookings
SELECT
mbs.firstname || ' ' || mbs.surname as member,
facs.name AS facility,
CASE
WHEN
mbs.memid = 0 THEN facs.guestcost * bks.slots
ELSE
facs.membercost * bks.slots
END AS cost
FROM
cd.members AS mbs
INNER JOIN cd.bookings AS bks ON mbs.memid = bks.memid
INNER JOIN cd.facilities AS facs ON bks.facid = facs.facid
WHERE
bks.starttime >= '2012-09-14'
AND
bks.starttime < '2012-09-15'
AND
(
(mbs.memid = 0 and bks.slots*facs.guestcost > 30)
OR
(mbs.memid != 0 and bks.slots*facs.membercost > 30)
)
ORDER BY cost DESC
Produce a list of all members, along with their recommender, using subqueries.
SELECT DISTINCT
mems.firstname || ' ' || mems.surname AS member,
CASE
WHEN mems.recommendedby IS NOT NULL THEN
(SELECT recs.firstname || ' ' || recs.surname
FROM cd.members as recs
WHERE recs.memid = mems.recommendedby)
ELSE NULL
END AS recommender
FROM
cd.members AS mems
ORDER BY member ASC
For every value of member, the subquery is run once to find the name of the individual who recommended them (if any). A subquery that uses information from the outer query in this way (and thus has to be run for each row in the result set) is known as a correlated subquery.
Produce a list of costly bookings, using a subquery
SELECT member, facility, cost
FROM (
SELECT
mems.firstname || ' ' || mems.surname AS member,
facs.name AS facility,
CASE
WHEN mems.memid = 0 THEN bks.slots * facs.guestcost
ELSE bks.slots * facs.membercost
END as cost
FROM
cd.members mems
INNER JOIN cd.bookings bks ON mems.memid = bks.memid
INNER JOIN cd.facilities facs ON facs.facid = bks.facid
WHERE
bks.starttime >= '2012-09-14' AND bks.starttime < '2012-09-15'
) AS bookings
WHERE
cost > 30
ORDER BY cost DESC
Subqueries in the FROM clause are referred to as inline views.
Insert some data into a table
INSERT INTO cd.facilities VALUES (9, 'Spa', 20, 30, 100000, 800)
Insert multiple rows of data into a table using VALUES
INSERT INTO cd.facilities
(facid, name, membercost, guestcost, initialoutlay, monthlymaintenance)
VALUES
(9, 'Spa', 20, 30, 100000, 800),
(10, 'Squash Court 2', 3.5, 17.5, 5000, 80)
Postgres allows you to use VALUES wherever you might use a SELECT.Similarly, it’s possible to use SELECT wherever you see a VALUES. See next example
Insert multiple rows of data into a table using SELECT
INSERT INTO cd.facilities
(facid, name, membercost, guestcost, initialoutlay, monthlymaintenance)
SELECT 9, 'Spa', 20, 30, 100000, 800
UNION ALL
SELECT 10, 'Squash Court 2', 3.5, 17.5, 5000, 80;
Insert calculated data into a table
INSERT INTO cd.facilities
(facid, name, membercost, guestcost, initialoutlay, monthlymaintenance)
VALUES
(
(SELECT MAX(facid) FROM cd.facilities) + 1,
'Spa', 20, 30, 100000, 800
)
Update some existing data
UPDATE
cd.facilities
SET
initialoutlay = 10000
WHERE
facid = 1
Update multiple rows and columns at the same time
UPDATE
cd.facilities
SET
membercost = 6,
guestcost = 30
WHERE
facid IN (0,1)
Update a row based on the contents of another row
UPDATE
cd.facilities
SET
membercost = (SELECT membercost from cd.facilities WHERE facid = 0) * 1.1,
guestcost = (SELECT guestcost from cd.facilities WHERE facid = 0) * 1.1
WHERE
facid = 1
Update a row based on the contents of another row - method 2
UPDATE cd.facilities AS facs
SET
membercost = facs2.membercost * 1.1,
guestcost = facs2.guestcost * 1.1
FROM (SELECT * FROM cd.facilities WHERE facid = 0) AS facs2
WHERE facs.facid = 1;
Delete all bookings
DELETE FROM cd.bookings
Delete a member from the cd.members table
DELETE FROM
cd.members
WHERE memid = 37
Delete based on a subquery
DELETE FROM
cd.members AS mems
WHERE
mems.memid NOT IN (
SELECT memid FROM cd.bookings
)
Count the number of facilities
SELECT COUNT(*) FROM cd.facilities;
Count the number of expensive facilities
SELECT count(*) FROM cd.facilities WHERE guestcost >=10
Count the number of recommendations each member makes.
SELECT
recommendedby,
count(*)
FROM
cd.members mbs
WHERE recommendedby IS NOT NULL
GROUP BY recommendedby
ORDER BY recommendedby
For each distinct value of recommendedby, get me the number of times that value appears
List the total slots booked per facility
SELECT facid, sum(slots) AS "Total Slots"
FROM cd.bookings
group BY facid
ORDER BY facid;
List the total slots booked per facility in a given month
SELECT
facid,
SUM(slots) AS "Total Slots"
FROM
cd.bookings
WHERE
starttime >= '2012-09-01' AND starttime < '2012-10-01'
GROUP BY facid
ORDER BY "Total Slots"
List the total slots booked per facility per month
SELECT
facid,
EXTRACT(month from starttime) AS month,
sum(slots) AS "Total Slots"
FROM cd.bookings
WHERE
starttime >= '01-01-2012'
AND starttime < '01-01-2013'
GROUP BY facid, month
ORDER BY facid, month;
Find the count of members who have made at least one booking
SELECT COUNT(DISTINCT memid) FROM cd.bookings
List facilities with more than 1000 slots booked
SELECT
facid,
SUM(slots) AS "Total Slots"
FROM
cd.bookings bks
GROUP BY facid
HAVING SUM(slots) > 1000
ORDER BY facid
Find the total revenue of each facility
SELECT
facs.name,
SUM((CASE
WHEN bks.memid = 0 THEN bks.slots * facs.guestcost
ELSE bks.slots * facs.membercost
END)) AS revenue
FROM
cd.bookings bks
INNER JOIN cd.facilities facs ON bks.facid = facs.facid
GROUP BY facs.name
ORDER BY revenue
Find facilities with a total revenue less than 1000
SELECT * FROM (
SELECT
facs.name,
SUM(CASE
WHEN bks.memid = 0 THEN bks.slots * facs.guestcost
ELSE bks.slots * facs.membercost
END) AS revenue
FROM
cd.bookings bks
INNER JOIN cd.facilities facs ON bks.facid = facs.facid
GROUP BY facs.name
) AS result
WHERE revenue < 1000
ORDER BY revenue ASC
Output the facility id that has the highest number of slots booked
SELECT
facid,
SUM(slots) AS "Total Slots"
FROM
cd.bookings AS bks
GROUP BY facid
ORDER BY "Total Slots" DESC
LIMIT 1
In the event of a tie, we’ll only get one result
Output the facility id that has the highest number of slots booked using Common Table Expressions
WITH sum AS (SELECT facid, SUM(slots) AS totalslots
FROM cd.bookings
GROUP BY facid
)
SELECT facid, totalslots
FROM sum
WHERE totalslots = (SELECT MAX(totalslots) FROM sum);
List the total slots booked per facility per month, part 2, using CTEs
WITH monthlysum AS (
SELECT
facid,
extract(MONTH from starttime) as month,
SUM(slots) as slots
FROM
cd.bookings
WHERE
starttime >= '2012-01-01' AND starttime < '2013-01-01'
GROUP BY facid, month
ORDER BY facid
)
SELECT
facid,
month,
sum(slots)
FROM
monthlysum
GROUP BY
rollup(facid, month)
ORDER BY facid, month
ROLLUP produces a hierarchy of aggregations in the order passed into it: for example, ROLLUP(facid, month) outputs aggregations on (facid, month), (facid), and (). Alternatively, if we instead want all possible permutations of the columns we pass in, we can use CUBE rather than ROLLUP. This will produce (facid, month), (month), (facid), and (). ROLLUP and CUBE are special cases of GROUPING SETS. GROUPING SETS allow you to specify the exact aggregation permutations you want.
List the total hours booked per named facility
SELECT
facs.facid,
facs.name,
trim(to_char(SUM(bks.slots) * 0.5, '9999.99')) AS "Total Hours"
FROM
cd.facilities facs
INNER JOIN cd.bookings bks ON facs.facid = bks.facid
GROUP BY facs.facid, facs.name
ORDER BY facs.facid
List each member’s first booking after September 1st 2012
SELECT mems.surname, mems.firstname, mems.memid, min(bks.starttime) AS starttime
FROM cd.bookings AS bks
INNER JOIN cd.members AS mems ON
mems.memid = bks.memid
WHERE starttime >= '2012-09-01'
GROUP BY mems.surname, mems.firstname, mems.memid
ORDER BY mems.memid;
Produce a list of member names, with each row containing the total member count
SELECT COUNT(*) over(), firstname, surname
FROM cd.members
ORDER BY joindate
Produce a numbered list of members
SELECT
rank() over(ORDER BY joindate ASC) AS row_number,
mems.firstname,
mems.surname
FROM
cd.members mems
Output the facility id that has the highest number of slots booked, again
SELECT facid, total
FROM (
SELECT
facid,
SUM(slots) AS total,
rank() over (ORDER BY SUM(slots) desc) AS rank
FROM cd.bookings
GROUP BY facid
) AS ranked
WHERE
rank = 1
Find the top three revenue generating facilities
SELECT name, rank
FROM
(SELECT
facs.name,
rank() over (ORDER BY SUM(
CASE
WHEN bks.memid = 0 THEN bks.slots * facs.guestcost
ELSE bks.slots * facs.membercost
END
) DESC)
FROM
cd.facilities AS facs
INNER JOIN cd.bookings AS bks ON bks.facid = facs.facid
GROUP BY name
) AS rankings
WHERE rank <= 3
ORDER BY rank ASC
Format the names of members
SELECT
trim(mbs.surname || ', ' || mbs.firstname) as name
FROM
cd.members mbs
Find facilities by a name prefix
SELECT
*
FROM
cd.facilities facs
WHERE
facs.name LIKE 'Tennis%'
Perform a case-insensitive search
SELECT
*
FROM
cd.facilities facs
WHERE
facs.name ILIKE 'tennis%'
Find telephone numbers with parentheses
SELECT memid, telephone FROM cd.members WHERE telephone ~ '[()]';
Pad zip codes with leading zeroes
SELECT LPAD(zipcode::text, 5, '0') as zip FROM cd.members
Count the number of members whose surname starts with each letter of the alphabet
SELECT
substr(surname, 1, 1) as letter,
COUNT(*)
FROM
cd.members
GROUP BY letter
ORDER BY letter
Window function - example 1
SELECT
last_name,
salary,
department,
rank() OVER (
PARTITION BY department
ORDER BY salary
DESC)
FROM employees;
Result:
last_name salary department rank
Jones 45000 Accounting 1
Williams 37000 Accounting 2
Smith 55000 Sales 1
Adams 50000 Sales 2
Johnson 40000 Marketing 1
Window function - example 2
SELECT *
FROM
(
SELECT last_name,
salary,
department,
rank() OVER (
PARTITION BY department
ORDER BY salary
DESC
)
FROM employees)
sub_query
WHERE rank = 1;
Result:
last_name salary department rank
Jones 45000 Accounting 1
Smith 55000 Sales 1
Johnson 40000 Marketing 1
Calculate a rolling average of total revenue over the previous 15 days
select date, avgrev from (
-- AVG over this row and the 14 rows before it.
select dategen.date as date,
avg(revdata.rev) over(order by dategen.date rows 14 preceding) as avgrev
from
-- generate a list of days. This ensures that a row gets generated
-- even if the day has 0 revenue. Note that we generate days before
-- the start of october - this is because our window function needs
-- to know the revenue for those days for its calculations.
( SELECT
generate_series('2012-07-10'::timestamp, '2012-08-31'::timestamp, '1 day')::date AS date
) AS dategen
left outer join
-- left join to a table of per-day revenue
(select bks.starttime::date as date,
sum(case
when memid = 0 then slots * facs.guestcost
else slots * membercost
end) as rev
from cd.bookings bks
inner join cd.facilities facs
on bks.facid = facs.facid
group by cast(bks.starttime as date)
) as revdata
on dategen.date = revdata.date
) as subq
where date >= '2012-08-01'
order by date;